6 : Statistiques – 1e L
I. Généralités
1. Vocabulaires
a) Population – Variable
Effectuer une étude statistique consiste à collecter, organiser et exploiter des informations sur un ensemble appelé population, délimité par une propriété commune.
Cette population est constituée d’individus ou unités statistiques, qui peuvent être des objets, des idées, des êtres vivants…
La propriété étudiée est appelée variable ou caractère.
Le caractère est qualitatif lorsque les valeurs prises ne sont pas des nombres, et quantitatif, lorsque les valeurs prises sont des nombres.
Un caractère quantitatif peut être discret si les valeurs prises sont isolées, ou continu s’il peut prendre toutes les valeurs possibles d’un intervalle.
b. Effectifs – Fréquence – Classes
L’effectif total est le nombre d’individus de la population.
On note en général x1, x2, …, xn les valeurs prises par la variable étudiée et ni le nombre d’individus sur lesquels on a observé la valeur xi. ni est appelé effectif de la valeur xi de la variable.
La série statistique ainsi définie se note (xi , ni). L’effectif total est alors.
N = \displaystyle\sum_{i=1}^n n_i = n_1 + n_2 + ... + n_n.
~Le rapport ~\dfrac{n_i}{N} = f_i est appelé fréquence de x_i
On a :
\bullet ~~ 0 \leq f_i \leq 1 quel que soit i
\bullet ~\displaystyle\sum_{i=1}^n f_i = f_1 + f_2 + ... + f_n = \displaystyle\sum_{i=1}^n \dfrac{n_i}{N} = \dfrac{\displaystyle\sum_{i=1}^n n_i}{N} = 1
\bullet~ 100.f_i donne le pourcentage des individus ayant le caractère x_i.
Lorsque le caractère est continu, on ne peut pas considérer chaque valeur séparément, on regroupe alors ces valeurs par classe.
De même lorsque l’effectif est assez important, il est plus commode de regrouper les valeurs par classe.
Exemple :
La population étudiée est l’ensemble des élèves d’une classe. Le caractère étudié est la note obtenue lors d’un certain examen. Les notes obtenues sont :
12 12 14 5 8 8 9 16 15 7 6 10 10 12 9 9 10 7 6 10 11 9 7 9 11
Ecrivons cette série de notes dans l’ordre croissant :
5 6 6 7 7 7 8 8 9 9 9 9 9 10 10 10 10 11 11 12 12 12 14 15 16
On voit que 1 élève a eu 5, deux ont eu 6, …. On peut réécrire cette série sous forme de tableau :

Effectifs cumulés – Fréquences cumulées
Considérons une série à caractère quantitatif xi. On ordonne les valeurs dans l’ordre croissant : x1 < x2 <…< xk.
Si ni est l’effectif de la valeur xi, on appelle effectif cumulé croissant jusqu’à la ie valeur le nombre : c’est le nombre des individus présentant une modalité inférieure à xi .

Ce tableau nous donne le nombre d’élèves qui ont eu une note inférieure à une note donnée. Par exemple, 6 élèves ont eu une note inférieure ou égale à 7, 13 n’ont pas eu la moyenne…
On définit de même :
– La fréquence cumulée croissante
\displaystyle\sum_{j=1}^i f_j = f_1 + f_2 + ... + f_i ou N est l’effectif total de la population.

2. Diagrammes
Un diagramme est une représentation graphique de la série. Il permet de visualiser ensemble les données statistiques.
a) Diagramme à bandes. Diagramme à bâtons
On porte en abscisses les valeurs de la variable x et en ordonnées les effectifs. Les effectifs sont représentés par des rectangles (bandes) verticales de longueurs proportionnelles aux effectifs. On peut remplacer les bandes par des segments : on obtient un diagramme en bâtons.
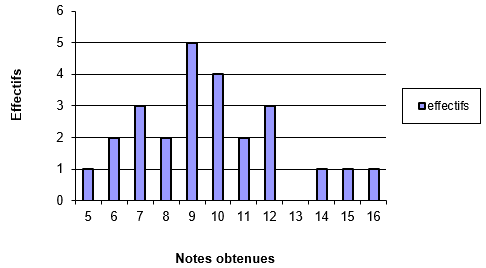
b) Diagramme à une seule bande
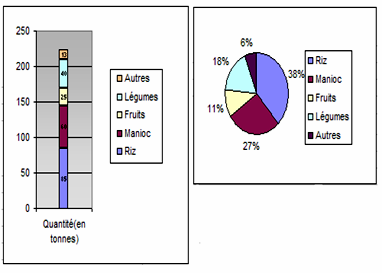
La longueur d’une bande est partagée proportionnellement aux effectifs ou aux fréquences.
Exemple : Voici la production agricole annuelle d’une certaine commune rurale :

c) Diagramme à secteur
C’est un diagramme de même type que le diagramme à une seule bande. Le disque est partagé en secteurs dont les angles sont proportionnels aux effectifs.
c) Histogrammes
Cas d’une série continue ou série classée.
On porte en abscisses les valeurs de la variable x et en ordonnées les effectifs. L’effectif est représenté par un rectangle dont la base est égale à l’étendue de la classe et la hauteur proportionnelle à l’effectif.
Exemple
Dans l’exemple précédent, regroupons les notes en classes d’amplitude 2
On obtient le tableau suivant :

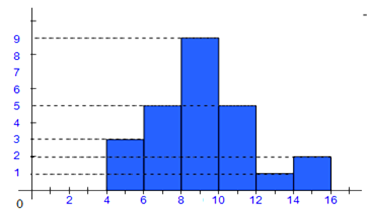
Polygones des effectifs
En reliant les extrémités des bâtons, on obtient le polygone des effectifs.
Dans le cas des histogrammes, on prend les centres des classes.
II. Caractéristiques d’une série statistique
Un caractéristique est une grandeur qu’on utilise pour résumer une série statistique.
On distingue deux sortes de caractéristique : caractéristiques de position et caractéristiques de dispersion.
1. Caractéristique de position
a) le mode :
Le mode ( ou dominante) est la valeur la plus fréquente de la variable. C’est la variable qui a le plus grand effectif.
Le mode est défini même si la variable est qualitative.
Pour une série classée, dont les classes sont d’égal effectif, la classe modale est la classe qui correspond au plus grand effectif.
Si une série peut posséder un seul mode on dit qu’elle est unimodale. Si elle en possède plusieurs, on dit qu’elle est plurimodale.
b) la moyenne
Définition :
La moyenne arithmétique d’une série statistique est égale à la somme des valeurs du caractère divisées par leur nombre.
i- Cas des données énumérées :
\overline{x} = \dfrac{x_1 + x_2 + ... + x_k}{N} = \dfrac{1}{N} \displaystyle\sum_{i=1}^k x_1
ii- si la série est donnée par sa distribution d’effectifs, les valeurs x1, x2, …, xn ayant respectivement pour effectifs n1, n2, ..,nk , alors :
\overline{x} = \dfrac{n_1 x_1 + n_2 x_2 + ... + n_k x_k}{N} = \dfrac{\displaystyle\sum_{i=1}^k n_i x_i}{\displaystyle\sum_{i=1}^k n_i}
iii- Cas où les valeurs sont regroupées en classes : les n_i valeurs de la i-ème classe sont supposées groupées au centre x_i de la classe. On revient ainsi au cas précédent.
Remarque :
\overline{x} = \dfrac{n_1 x_1 + n_2 x_2 + ... + n_k x_k}{N} = \dfrac{n_1}{N} x_1 + \dfrac{n_2}{N} x_2 + ... + \dfrac{n_k}{N} x_k
Donc si f_i est la fréquence de la variable x_i alors :
\overline{x} = \displaystyle\sum_{i=1}^k f_i x_i
Propriétés ( à établir en exercice) :
– Soit une série statistique sur une population et une partition de cette population en deux sous-populations d’effectifs respectifs n1 et n2. Si m1 etm2 sont les moyennes respectifs des deux sous-populations, alors la moyenne de la population est \overline{x} = \dfrac{n_1m_1 + n_2m_2}{n_1 + n_2}
– Si \overline{x} est la moyenne de la série (x_i~,~n_i)
~~ > alors la moyenne de la série (x_i - a~,~n_i) est \overline{x} - a
~~ > La moyenne de la série (h.x_i~,~n_i) est h.\overline{x}
Donc, si on pose y_i = ax_i + b alors la moyenne de la série (y_i~,~n_i) est \overline{y} = a.\overline{x} + b
c) La médiane
Définition
C’est la valeur de la variable qui partage la population en deux parties de même effectif : c’est donc la valeur M de xi telle que la moitié au plus des valeurs des xi soient inférieures à M et la moitié au plus des valeurs de xi supérieure à M
Détermination de la médiane :
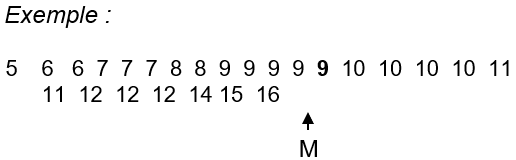
- Cas d’une série discrète
On range dans l’ordre croissant les valeurs de la variable, chaque valeur étant écrite autant de fois qu’elle est prise :
– Si le nombre de valeurs est impair, la médiane est la valeur du milieu.
– Si le nombre de valeurs est pair, on peut prendre comme médiane tout valeur comprise entre les deux valeurs au centre. Par convention, on prend la demi somme de ces deux valeurs.
M = \dfrac{x_i + x_{i+1}}{2} et x_{i+1} sont les valeurs au centre.
- Cas d’une série classée
On trace le polygone des effectifs cumulés croissants et celui des effectifs cumulés décroissants. La médiane M est le l’abscisse du point d’intersection de ces deux courbes.
Un autre manière de la déterminer est de tracer le polygone des effectifs cumulés (ou fréquence cumulées) et la droite d’équation y = \dfrac{N}{2}où N est l’effectif total de la population. La médiane est l’abscisse du point d’intersection de cette droite avec le polygone.
2. Caractéristique de dispersion
Une caractéristique de dispersion est utilisée pour évaluer la dispersion d’une série. On utilise le plus souvent la variance et l’écart type .
Variance. Ecart type
Définition
La variance d’une série est la moyenne des carrés des écarts à la moyenne.
V = n_1 (x - x_1)^2 + n_2 (x - x_2)^2 + ... + n_k (x - x_k)^2 = \dfrac{\displaystyle\sum_{i=1}^k n_i (x -x_i)^2}{\displaystyle\sum_{i=1}^k n_i}
L’écart type d’une série est la moyenne quadratique des écarts à la moyenne. C’est la racine carrée de la variance : \sigma = \sqrt{V}
Remarques :
Plus la variance est grande, plus la série est dispersée.
Plus la variance est petite (voisin de 0), pus la série est resserrée autour de la moyenne. La variance est une quantité positive ou nulle.
Méthode de calcul :
Même avec des valeurs observées x_i très simples, il arrive souvent que la moyenne \overline{x} soit un nombre décimal. Dans ce cas, le calcul de la variance V nécessite des calculs fastidieux.
La formule de Koenig : V = \dfrac{\displaystyle\sum_{i=1}^k n_i x_i^2}{N} - (\overline{x} )^2
(que vous allez démontrer en exercice) permet de simplifier les calculs.
Propriétés ( à établir en exercice) :
– La variance et l’écart-type de la série (x_i - a ~,~ n_i) sont indépendants de a : ce sont respectivement la variance et l’écart-type de (x_i ~,~ n_i)
– Si la variance et l’écart-type de la série (x_i ~,~ n_i) sont respectivement V et \sigma, alors la série (h.x_i ~,~ n_i) a pour variance V' = h^2 V et pour écart-type \sigma ' = |h| \sigma